[SQL 레코드 순서 응용4]
레코드 안의 순번을 활용하는 예제 - 테이블에 존재하는 시퀀스 찾기
앞 포스팅에서는 테이블에 존재하지 않는 시퀀스를 찾아 그룹화하여 출력하는 쿼리 예제를 살펴보았다. 오늘의 포스팅에서는 테이블에 존재하는 수열을 그룹화하여 활용해보는 예제를 실습해볼 것이다.
3. 테이블에 존재하는 시퀀스 구하기
이번 예제에서는 앞 포스팅의 예제와 출력 과정은 다르지만, 결과를 추출하는 기본적인 개념은 다르지 않다. 따라서, 앞선 예제에서 사용한 집합 지향적 방법과 절차 지향적 방법의 과정을 이용해 보도록 하겠다.
- 집합 지향적 방법 : 집합의 경계선 사용
집합 지향적인 방법으로 테이블에 존재하는 시퀀스를 구하는 것은, 존재하지 않는 시퀀스를 구하는 것보다 쿼리상으로 아래와 같이 훨씬 간단하다. MAX와 MIN 함수를 통해 시퀀스의 경계를 직접 구할 수 있기 때문이다.

하지만 쿼리상으로 이해가 잘 가지 않는 필자 본인을 위해서 아래와 같이 서브쿼리 내부에 있는 테이블을 출력해보았다.

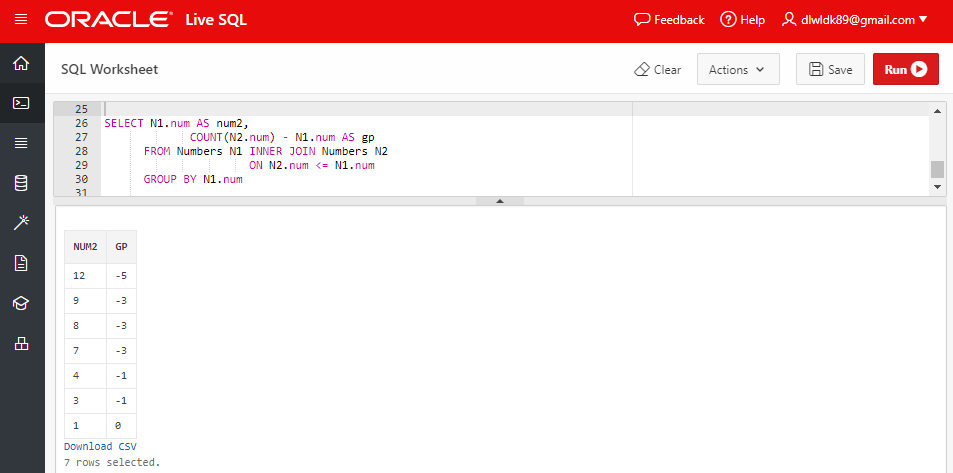
위의 쿼리를 쉽게 이해하기 위해서 FROM 구에서 만들어지는 테이블(INNER JOIN된 테이블)을 불러와보았다.
Numbers 테이블을 두 번 불러와 INNER JOIN을 하는데, 옆에서 표현한 같은색 그룹들의 count(num) - num 값이 동일한 것을 볼 수 있다.
결론적으로, count(num) - num 값의 의미는 "1부터 시작해서 해당 num까지 비어있는 숫자의 개수"라고 해석할 수 있다.
위의 서브쿼리에서 연산된 gp(위에서 구한 count(num) - num)값을 정리하면 아래의 쿼리 결과와 같으며, gp 필드로 그룹화하여 최종적으로 테이블에 존재하는 시퀀스 결과를 도출할 수 있다.
- 절차 지향적 방법 : 다음 레코드 하나와 비교
절차 지향형 방법도 기본적인 방식은 이전과 비슷하나, 코드가 비교적 길어진다. 아래의 예시 쿼리에서는 3개의 서브쿼리를 불러오게 되는데, 각 서브쿼리를 설명하며 아래 쿼리를 살펴보도록 하겠다.

TMP1 Table - 가장 내측의 첫번째 서브쿼리
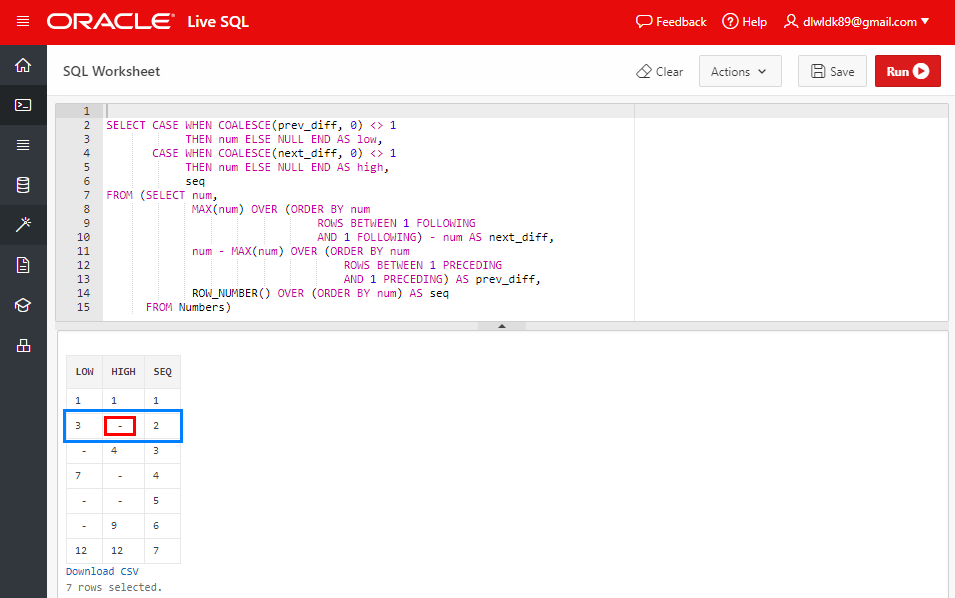
여기서는 현재 레코드와 전후의 레코드에 있는 num 필드의 차이를 구한다. 아래 그림에서 두번째 레코드(파란색 박스 레코드)를 설명하면 다음과 같다.
1. next_diff 값은 다음 레코드의 num 값인 4에서 현재 레코드의 3을 뺀 결과인 1 출력
-> 1이 아니라면 현재 레코드와 다음 레코드 사이에 비어있는 부분이 존재한다는 뜻을 내포함
2. prev_diff 값은 현재 레코드의 num 값인 3에서 이전 레코드의 1을 뺀 결과인 2 출력
-> 1이 아니라면 이전 레코드와 현재 레코드 사이에 비어있는 부분이 존재한다는 뜻을 내포함
3. seq는 행 번호를 붙인 것

TMP2 Table - 중간에 생성되는 두번째 서브쿼리
TMP2 테이블에서는 현재 레코드(num)과 이전, 다음 레코드에 있는 필드의 차이를 구한다. TMP1 테이블에서 빨간색 박스(두번째 행의 prev_diff)로 표시한 prev_diff = 2 값이 1이 아니므로, 파란색 박스(두번째 행)의 이전 레코드와 현재 레코드 사이에 빈값이 있다는 것을 의미한다고 위에서 설명하였다.
따라서, 이에 따라 아래 TMP2 테이블에서의 파란색 박스(두번째 행)의 high 값에 null을 출력해 주는 쿼리가 실행된다. low 필드도 마찬가지 방법으로 실행된다.
+ < COALESCE 함수 : COALESCE(a1, a2, a3, ... , ai) >
COALESCE 함수는 내부의 값을 읽어 null이 아닌 첫번째 값을 리턴해준다.
예제에서 사용되는 COALESCE(prev_diff, 0)의 경우에는 prev_diff 값이 null이면 0을 리턴하고, null이 아니면 prev_diff 값을 리턴해주게 된다.
TMP3 Table - 가장 바깥에 생성되는 세번째 서브쿼리
TMP2 테이블을의 결과에서 '3~4' 또는 '7~9'처럼 동일한 레코드에 low 필드와 high 필드가 존재하지 않는 시퀀스가 존재하므로, TMP3 테이블에서는 이를 정리해 주는 쿼리를 실행해준다.

이렇게 생성된 테이블에서 WHERE low IS NOT NULL로 불필요한 레코드를 제거하면 최종 결과를 구할 수 있다.
이처럼 절차 지향적 방법의 쿼리의 코드는 다소 길지만, 순서대로 차근차근 보면 이해하는데에는 그다지 어렵지 않은 코드이다.
12번 포스팅부터 오늘의 15번 포스팅까지, 레코드에 매겨진 순번을 활용하여 다양한 응용 예제를 살펴보았다.
다음 포스팅부터는 '갱신'을 어떻게 하면 더 효율적으로 할 수 있는지에 관해 살펴볼 예정이다.
'Data Analysis > SQL' 카테고리의 다른 글
| [SQL] 18. SQL 갱신 응용1 (예제 - NULL값 채우기) (0) | 2019.07.28 |
|---|---|
| [SQL] 17. SQL 실습환경 갖추기 (feat. HeidiSQL with MySQL) (0) | 2019.07.24 |
| [SQL] 14. SQL 레코드 순서 응용3 (예제 - 테이블에 존재하지 않는 시퀀스 찾기) (0) | 2019.07.21 |
| [SQL] 13. SQL 레코드 순서 응용2 (예제 - 레코드 순번 활용 : 중앙값 구하기) (0) | 2019.07.21 |
| [SQL] 12. SQL 레코드 순서 응용1 (예제 - 레코드에 순번 붙이기) (0) | 2019.07.20 |




댓글